FiveThirtyEight’s NBA Predictions are Underperforming Simple Team Metrics
But their algorithms account for fatigue, travel distance, and altitude — cool!
FiveThirtyEight’s predictions
FiveThirtyEight publishes point spreads and win probabilities for every NBA game. They actually publish two sets of predictions: RAPTOR and Elo. Here’s a brief snippet FiveThirtyEight provides for each:
Our player-based RAPTOR forecast doesn’t account for wins and losses; it is based entirely on our NBA player projections, which estimate each player’s future performance based on the trajectory of similar NBA players…
Elo ratings — which power the pure Elo forecast — are a measure of team strength based on head-to-head results, margin of victory and quality of opponent.
How exactly do these algorithms work? Well, let’s just say it involves a Pythagorean expectation with a regular-season exponent of 14.3 and a playoffs exponent of 13.2. You can read the full 2,814-word description here.
The case for simplicity
When it comes to making predictions, unnecessary complexity is something you always want to avoid. If a simpler model performs as well as a more complicated one, you take the simpler one. Smaller, more parsimonious models are easier to interpret, and they tend to give better predictions than complex models with more moving parts.
It seems to me that in order to justify their complexity, FiveThirtyEight’s point spreads have to be considerably more predictive than simpler metrics like team win percentage or average points per game differential (PPGD). Why bother with a complicated metric if it isn’t more prognostic?
Thus, the purpose of this analysis is to examine whether FiveThirtyEight’s algorithms are performing any better than simple team metrics so far in the 2019–2020 NBA season.
Dataset
FiveThirtyEight lists their predictions for the entire NBA season to date. I used these predictions to create a dataset where each row shows the RAPTOR spread, Elo spread, and actual result for one NBA game. The dataset consists of all 778 games played through Feb. 8, 2020. Here’s what it looks like:

Variables
The response variable of interest is the game result, defined as the home team’s score minus the away team’s score. Predictors of interest include:
- RAPTOR spread
- Elo spread
- Difference in team win percentages to date (home team minus away)
- Difference in average PPG differentials to date (home team minus away)
The latter two aren’t in the dataset above but are easy to derive programmatically. For each row, you subset the prior games involving the home and away team, calculate win percentage and average PPG differential for each team, and subtract the two values.
Analyses
Correlation matrix
All we really need to answer the substantive question of interest is a correlation matrix for the 5 variables defined above:

Looking at the rightmost column, we see that the most prognostic variable is the PPG differential between the home and away team, followed by ELO, Raptor, and win percentage differential.
Sensitivity to burn-in period
The two team metrics require a burn-in period, because for example you can’t calculate win percentage or average win differential for each team’s first game of the season. And these metrics are bound to be unstable early on, e.g. lots of win percentages of 0% and 100%. For the above results, I excluded the very early games of the season — games for which one or both teams had played fewer than 3 games previously.
Naturally, it’s of interest whether the results are sensitive to the burn-in period selected. I’d expect the team metrics to perform even better relative to RAPTOR and Elo for longer burn-in periods, as you increasingly stabilize these signals in the early part of the test dataset.
Here’s how the correlations with game result compare as the burn-in period varies from 1, the absolute minimum, to 20 (~1/4 of NBA season).
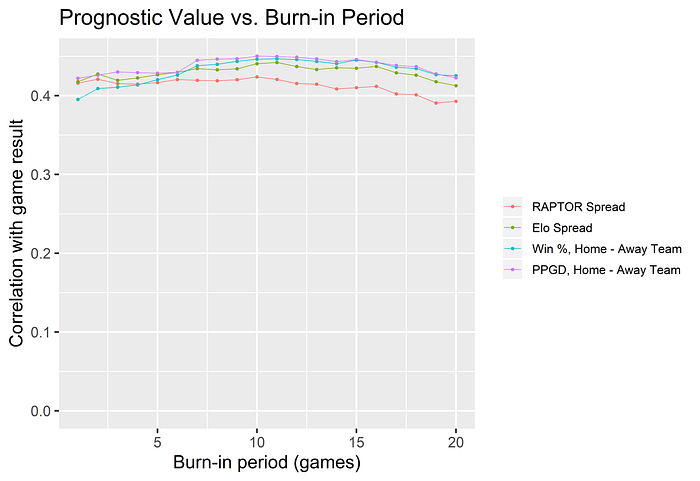
For all burn-in periods ≥ 7 days, the two simple team metrics outperform RAPTOR and Elo.
Conclusions
It seems to me that FiveThirtyEight’s RAPTOR and Elo algorithms are overly complicated for what they actually deliver: worse predictions than the most basic team metrics. I suspect their models are badly overfit.
